



|
A Cognition Briefing Contributed by: Narayanan U. Edakunni, University of Edinburgh
Introduction
In recent years, with the development of fast and accurate machine learning methods, it has been possible to learn the dynamics of a robot efficiently. When learning the dynamics, a robot must use a learning algorithm that is able to process the data and learn in real time. The robot tries to learn the mapping between the command applied and the resulting change in the state of the robot. When a new state change is desired the learnt mapping is used to predict the command that needs to be applied to reach the state. Hence we see that the operation of the robot happens simultaneously with learning. A robot operating in the real world needs to interact with its environment in real time which results in a constantly changing state of the robot. This makes it important for the robot to learn from a single data point at a time without having to store away the data. This form of learning where data points are discarded after learning is termed as online learning. The tight constraints on memory and computational resources imposed by this form of learning leads to difficulties in formulating such online learning algorithms. One of the successful algorithms that meets these requirements is the Locally Weighted Projection Regression (LWPR)[1] which tries to learn the underlying mapping between the state of the robot and the command that produced it using a weighted local linear approximation. This algorithm has the nice characteristics of being able to operate in real time with limited memory. Furthermore, unlike conventional localised learning algorithms LWPR learns the local models independent of each other, which makes it robust against negative interference[2,3]. The independent formulation also lends it a distributed learning capability; being able to learn different parts of a function simultaneously. LWPR's success has been demonstrated by modelling such complex tasks as juggling in robots[4]. One of the drawbacks of LWPR is that it has a lot of open parameters that need to be tuned to obtain the optimal learning behaviour. This is different from behaviour in humans who do not need to fix open parameters. The solution to this lies in Bayesian learning. According to the Bayesian school of thought, parameters of a model have an associated probability distribution which avoids the need to tune the parameters.
Bayesian Learning
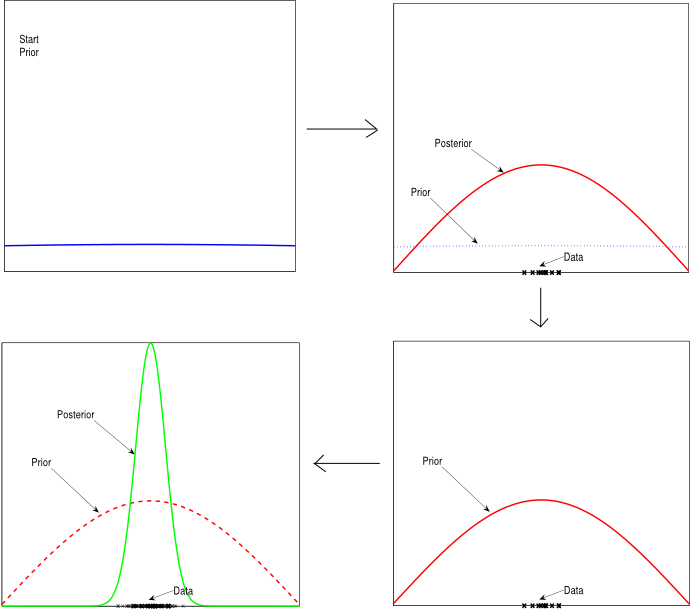
Fig. 1 : Illustrates the process of probability update during Bayesian online learning. The Bayesian framework can hence be used effectively to model the dynamics of a robot. We start with a certain prior probability of the dynamics model. We then apply a random command to the system (usually called motor babbling), observe the change of state this causes and accordingly come up with our posterior belief about the dynamics of the system. This posterior belief then serves as the prior for the next step of learning. This way the model of dynamics or equivalently the parameters of the model gets updated at each time step to reflect the experience so far [6]. The Randomly Varying Coefficient (RVC) model[7] is a probabilistic model based on this paradigm of Bayesian probabilistic online learning that combines the virtues of a Bayesian probabilistic framework and LWPR. In RVC the idea of independent localised learning is reformulated as a Bayesian probabilistic model thus resulting in an efficient yet robust learning algorithm suited for real time learning tasks like the one shown in Fig. 2. The figure illustrates an experiment where a composite controller consisting of a combination of feedforward and low gain feedback commands was used to control the joints of a simulated DLR arm. The feedforward command in turn was produced from an inverse dynamics model of the robot arm learnt online by an RVC model. The aim of the experiment was to learn an accurate model for the inverse dynamics of the robot arm online, while the robot performed a figure-8 pattern. The result of the experiment is shown in Fig. 2(b) where the pattern performed by the robot is shown at different stages of learning. The speedy convergence of the tracking establishes the effectiveness of the RVC method in real time learning.

Figure 2.a: The DLR arm © http://www.dlr.de
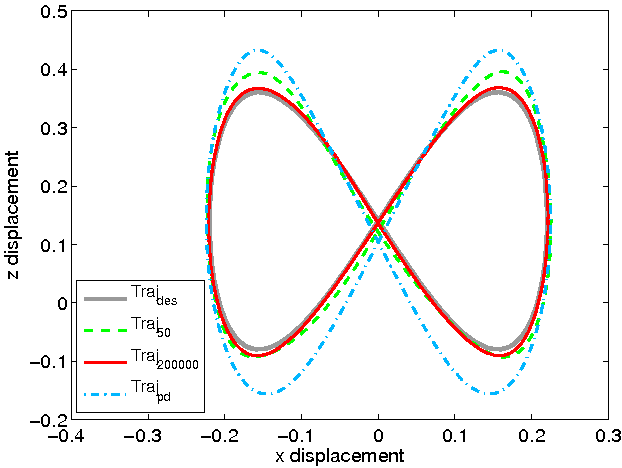
Figure 2.b: Learning of the dynamics of a simulated DLR arm using RVC. The tracking performance after different iterations of learning is shown. Traj_des represents the desired trajectory. Traj_pd represents a PD controller without any model of the dynamics. Traj_50 and Traj_200000 represents the tracking performance of model learnt by RVC after training over 50 and 200000 data points respectively. References
|