



|
A Cognition Briefing Contributed by: Timothy Hospedales,University of Edinburgh
Introduction
Another aspect to this problem is the \emph{relation} between the cues, which is indirectly related to the state of interest. Suppose while searching: i) you see motion on the horizon, but of a different color than your dog's, ii) you hear a bark, but in a different tone to your dog's, iii) you see motion or hear barking, but in a different direction entirely to the one that your pet ran off in. Any of these cases might suggest that the particular observed cue is related to some other animal than yours and should be discounted in your search. This example is a problem of ''causal structure'' inference, where the causality of your observation ("''did this observation indeed come from my pet, or some other pet?''") is uncertain and to be computed. These two problems are clearly related in that knowledge or uncertainty about one can create knowledge or uncertainty about the other. We give an example of these types of multisensory perception problems from three synergistic perspectives.
Research
For multisensory observations, in the absence of uncertainty about causality, the ideal observer's computation is known as ''sensor fusion.'' Here, a common parametric form describes observations as linear Gaussian functions of the source state (Ernst and Bulthoff, 2004). This has two (intuitive) consequences. i) The optimal estimate of the state is given by the precision weighted mean of all the observations, such that more reliable observations are given higher weighting. ii) The addition of any further modalities of observation can only increase the precision of the state inference, which is given by the sum of the precisions for each observation modality. So suppose (plausibly) that visual and auditory localization are similarly precise on a foggy evening, while vision is much more precise than audition during the day and vici-versa during the night. Then, on a foggy evening, the ideal observer would rely on an approximately equally weighted combination of vision and audition. During day or night, the ideal observer would rely almost entirely on vision and audition respectively. In this way using audition and vision together is guaranteed to be helpful in localization. In the presence of causal uncertainty, the ideal observation must also determine the causality of the observations while optimally estimating the state of interest. (In Bayesian network terminology, these two unknowns are ''conditionally dependent''.) This is known as ''causal structure inference'' or ''data association'' and is formally a Bayesian model selection problem (MacKay, 2003). Assuming again that observations are linear Gaussian functions of the state, this model selection will depend on two things: The agreement between the observations as well and the match between the observations and their known statistics. (E.g. to optimally locate the lost pet, the identity of an observed bark also needs to be determined. This will in turn depend on the match between the bearing of the bark and the last known pet location as well as the tone of the bark and the known tone of the pet). Applying this theoretical modeling approach, we aim to build artificial cognitive systems which are as close as possible to the ideal observer given the available computational resources. (Exact ideal observer inference may be intractable). We can also investigate how closely the perceptual performance of humans comes to that of the ideal observer.
Artificial Cognitive Systems
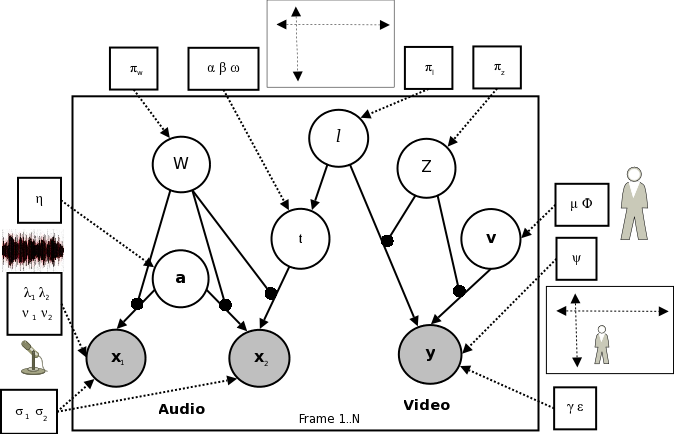
Figure 1: Bayesian network describing the potential correlations among audio microphone elements x_1, x_2 and camera image y as function of source location l, audibility W and visibility Z.
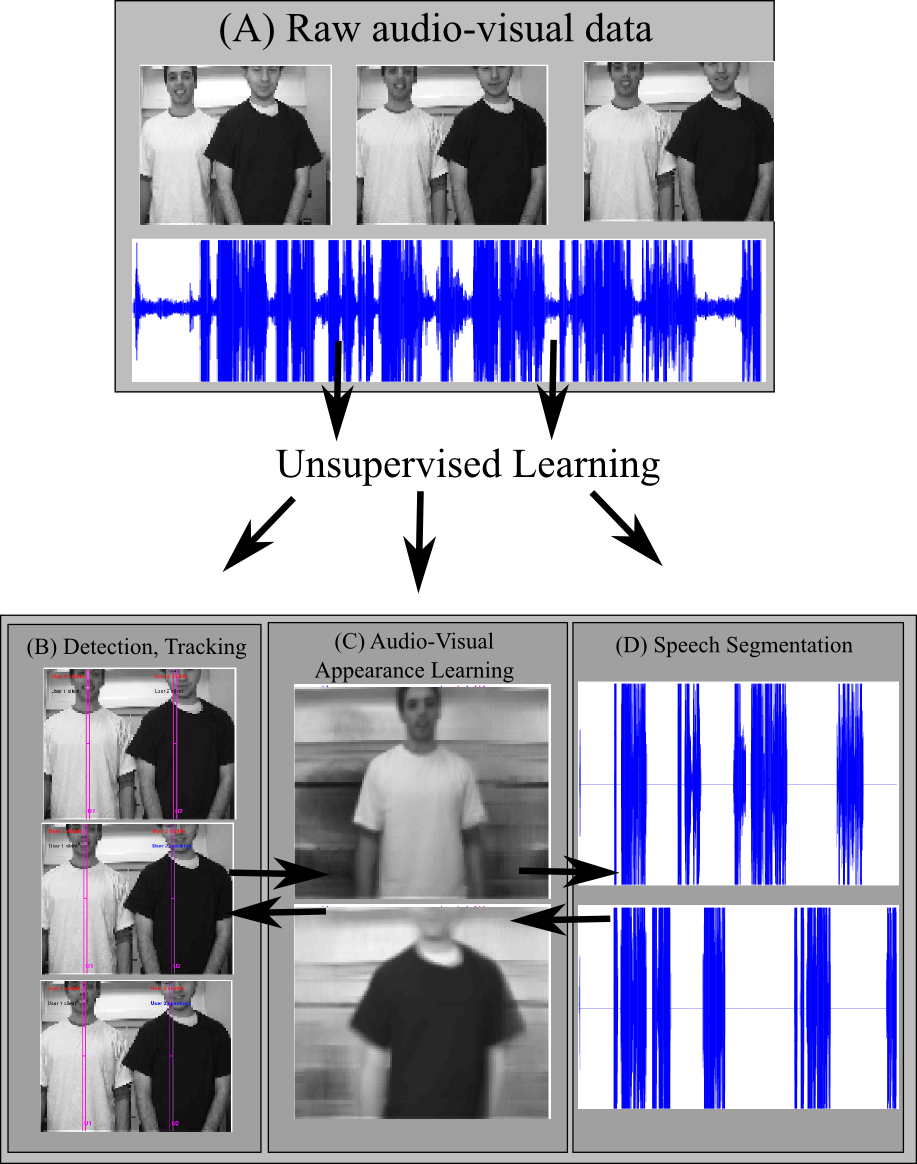
Figure 2: Operation schematic for audio-visual scene understanding system. Using raw data (a) as input for unsupervised learning and inference in the model (Fig. 1) allows tracking (b), appearance learning (c) and speech segmentation (d) The computer is equipped with an ideal observer Bayesian network model (Fig. 1) describing sources (e.g. people) in the world as potentially (but not necessarily) audible and/or visible. It also describes the potential correlation in these observations if a source is simultaneously both speaking and visible (via the dependence of the inter-microphone signal delay on the source position). No parameters of this model (e.g. what people look or sound like) are pre-specified. Given the chance to observe raw data of some people moving and speaking (Fig. 2a), the system bootstraps itself without supervision, learning the model parameters (e.g. people's visual appearance, Fig. 2c) from correlations in the data using expectation maximization (Bishop, 2006). It infers in real time the people's states, including where they are (Fig. 2b) and de-noised estimates of their appearance and speech. Simultaneously, (and purely by inferring the causal structure of the Bayesian network), the model effectively judges at each timestep whether each person is present, whether they are speaking and who said what (Fig. 2b,d). Note that unlike the lost dog example, the causal structure here is of intrinsic interest, as knowing who said what in a conversation may be crucial to its understanding. The ideal observer model effectively judges causal structure questions such as who said what (Fig. 2d) on the same bases described earlier: Whether the visual and auditory cues come from the same bearing, who was last thought to be at that bearing and the match between the visual and auditory cues with the parameters learnt for each person. In addition, the structure inference allows effective tracking through occlusion/silence in the visual/auditory modalities - a typical point of failure in traditional approaches.
Natural Cognitive Systems
More recently, with the theoretical models for causal structure inference described here, human multisensory perception is beginning to be seen as close to ideal even under causal uncertainty. In Kording et al (2007), for example, human subjects are presented with a very similar task to the lost dog or speaker localization tasks discussed earlier. Subjects observe a potentially location discrepant audio-visual stimuli which they must localize and judge for common causation or not. Subjects' perception of the stimuli exhibits the predictions of an optimal observer faced with multisensory observations of uncertain causality: i)~Their judgement of common causation depends on the agreement between the stimuli. ii)~When the stimuli are nearly in agreement their percept is almost the precision weighted mean of individual stimuli (because the stimuli almost certainly have common cause). When the stimuli are are in strong disagreement, people's percept is almost entirely independent of one modality (because the stimuli almost certainly do not have common cause).
Conclusions
References
|