|
A Cognition Briefing Contributed by: Francesco Orabona, IDIAP Research Institute, Martigny, Switzerland
Introduction
An immediate consequence of this setting is that an online learning system must face a potentially endless flow of training samples, and must therefore limit the number of samples taken into account when training, due to inevitable restrictions on the available resources (e.g., a finite computational power). In other words, regardless of the number of samples seen until a given moment, the algorithm should have a bounded complexity. Moreover note that online algorithms are typically simple to implement and they can handle more easily big quantity of data, compared to batch algorithms. We will briefly review the state of the art algorithms for online learning with kernels, with emphasis on the ones with bounded complexity.
Online Learning with Kernels
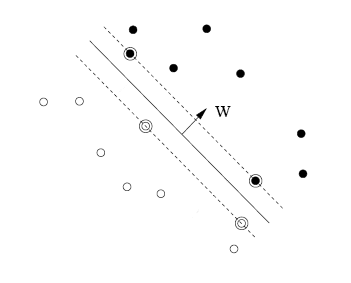
Figure 1. Maximum-margin separating hyperplane. Linear algorithms for binary classification find a separating hyperplane in the input space that divides the two classes. If such hyperplane exists, the problem is said to be linearly separable. In this case it is always possible to find a maximum-margin separating hyperplane which is at equal distance from the two classes. The distance between the hyperplane and the classes is thus maximal, and it is called margin. See Figure 1. The margin is related to the difficulty of the classification task. It is also linked to the generalization performance of the classifier. If the problem is not linearly separable we could think to use a non-linear separating surface, instead of a hyperplane. But to retain all simplicity of linear classifier, a common trick is to transform the data with a non-linear transform and then apply the linear algorithm (see for example Slow Feature Analysis [2] for a similar approach and a discussion on the biological plausibility of the method). This will result in a non-linear surface in the original space. Of course this comes at the expense of an increase of the input dimensionality and hence of the computational complexity of the algorithm. However in most of the algorithms we just need to access to the inner products between the samples. So we can use a function that is returning directly the inner product in the transformed space, from the original input samples. This function is called Kernel function and it is the core of the Support Vector Machine (SVM) algorithm. We can use kernels in online linear algorithms too, obtaining non-linear versions, almost for free. The price to pay is that the size of the solution will be proportional to the number of training samples. Note that the same is true for the SVM. This is of course unacceptable if you consider the fact that the number of training sample is potentially endless in the online setting. There is a big number of online learning algorithms in the scientific literature. The "quality" of an online algorithm is measured by how good its predictions are, and most of them provides a bound on the maximum number of mistakes they will commit in the worst case scenario. These bounds compare the performance of the algorithm to the best possible hypothesis in the same functional space. Often the algorithms itself are designed to have good bounds, that is to provide performance that are asymptotically close to the best hypothesis (that is with small "regret"). These bounds also provide a principled way to compare different algorithms. Note that a better bounds does not always imply better performance, but it often implies a better "controllability" of its behavior. We could draw a parallel between the preference for algorithms with bounds and the preference in robotics for actuators that have a mechanical design that simplifies the mathematical forms of the equations to control them. Online learning algorithms include, for example, the Perceptron algorithm [3]. More modern examples include the ROMMA algorithm of Li and Long [4], Gentiles ALMA algorithm [5], and the NORMA algorithm [6]. A framework of online learning for structured learning is the Passive-Aggressive online algorithm [7]. All these algorithms observe examples in a sequence of rounds, and construct the classification function incrementally, by storing a subset of the observed examples in their internal memory. The classification function is then defined by a combination of kernel function evaluated on the stored examples. This set of stored examples is the online equivalent of the support set in SVMs. Note all the above algorithms can be easily extended to the multiclass setting, see for example the MIRA algorithm [12]. Other interesting variants include the case of multiclass classification in which after the prediction the true label is not disclosed, but we only receive a binary feedback (right/wrong prediction). This setting is close to the reinforcement learning setting and even in this case it is possible to design good algorithms with mistake bounds [13]. Given the fact that many of the most important algorithms are based on the Perceptron, we will describe it in more details.
The Perceptron
Bounded testing time and Kernels
A different approach was followed in Orabona et al. [10] using online variant of the SVM with a limited number of support patterns called OISVM. Starting from this last algorithm Orabona et al. have proposed the Projectron [11]. The Projectron is based on the idea of approximating the new samples with the old ones, in order keep the size of the solution bounded, but at the same time retaining most of the accuracy of the solution. We briefly review in the following some budget online algorithms and the Projectron.
The Forgetron
The Random Budget Perceptron (RBP)
The Projectron
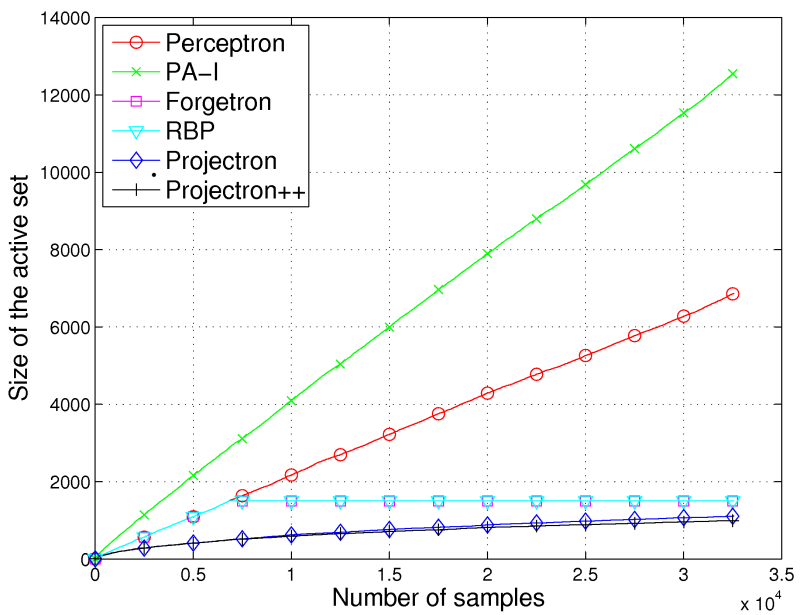
Results
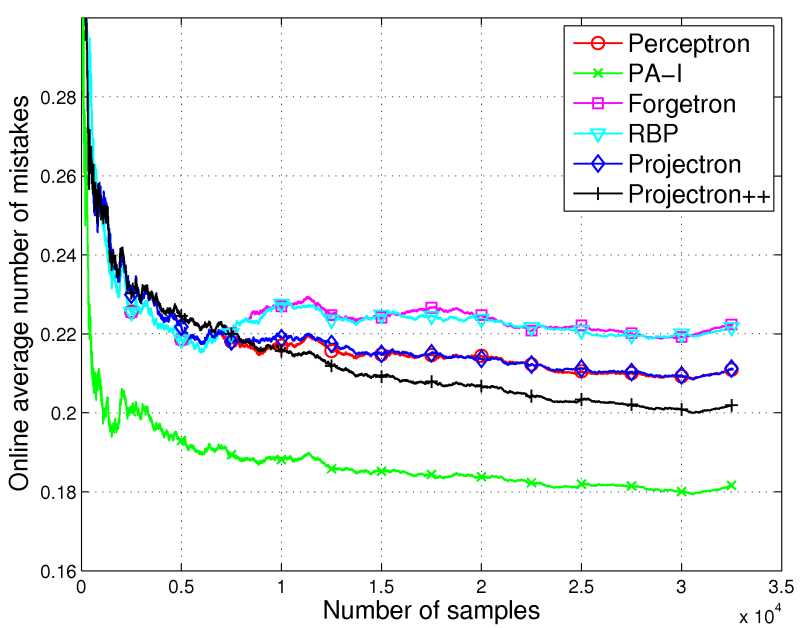
Figure 2. Online average number of mistakes vs number of training samples.
Conclusions
References
[2] L. Wiskott and T.J. Sejnowski. Slow feature analysis: Unsupervised learning of invariances. Neural Computation, 14(4):715-770, 2002. [3] F. Rosenblatt. The Perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 65, 386-407, 1958. [4] Y. Li and P. M. Long. The Relaxed Online Maximum Margin Algorithm. 46(1-3), 361-387, 2002. [5] C. Gentile. A new approximate maximal margin classification algorithm. J. Mach. Learn. Res., 2, 213-242, 2002. [6] J. Kivinen, A.J. Smola, and R.C. Williamson. Online learning with kernels. IEEE Trans. on Signal Processing, 52(8), 2165-2176, 2004. [7] K. Crammer, O. Dekel, J. Keshet , S. Shalev-Shwartz, and Y. Singer. Online passive-aggressive algorithms. Journal of Machine Learning Research, 7, 551-585, 2006 [8] K. Crammer, J. Kandola, and Y. Singer. Online classi?cation on a budget. Advances in Neural Information Processing Systems 16, 2003 [9] O. Dekel, S. Shalev-Shwartz, and Y. Singer. The Forgetron: a kernel-based Perceptron on a budget. SIAM Journal on Computing, 37, 1342-1372, 2007 [10] F. Orabona, C. Castellini, B. Caputo, J. Luo, and G. Sandini. Indoor place recognition using online independent support vector machines. In Proc. of the British Machine Vision Conference 2007, 1090-1099, University of Warwick, UK, September 2007 [11] F. Orabona, J. Keshet, and B. Caputo. The Projectron: a bounded kernel-based Perceptron. In Proc. of International Conference on Machine Learning (ICML08), Helsinki, Finland, July 2008 [12] K. Crammer and Y. Singer. Ultraconservative Online Algorithms for Multiclass Problems. Journal of Machine Learning Research, 3(Jan):951-991, 2003. [13] S. Kakade, S. Shalev-Shwartz, and A. Tewari. Efficient bandit algorithms for online multiclass prediction. In Proc. of the 25th Annual International Conference on Machine Learning (ICML 2008), Helsinki, Finland, July 2008 [14] N. Cesa-Bianchi, A. Conconi, and C. Gentile, Tracking the best hyperplane with a simple budget Perceptron. In Proc. of the 19th Conference on Learning Theory, 483-498, 2006
|